AuraQ has vast experience helping organisations find the gaps that can be filled to enhance their business. This could be to improve efficiency, integrate legacy systems or deliver new portals and strategic applications to create competitive advantage. Contact us to request a free, no obligation Gap Analysis.

Leveraging Machine Learning Capabilities in Application Development
What is machine learning?
In recent years, the digital sector has been transformed by artificial intelligence (AI). With tools such as ChatGPT and DALL-E, public access to AI resources is at an all-time high. However, with the rapid pace at which this emerging technology is being developed and released, it can become overwhelming to understand the terms being thrown around, let alone attempting to develop with this technology. This blog aims to highlight how low-code development can not only reduce this complexity, but also improve the implementation of AI in applications. The terms AI and machine learning (ML) are often used interchangeably. However, while AI is the ability of computers to perform complex tasks that would require a certain level of intelligence to complete, ML is an application of AI that uses mathematical models to continuously improve without direct instruction. Some of these models, such as neural networks that attempt to mimic the structure of the human brain, can become very complex and can help perform equally complex tasks. It is these complicated structures that form the foundation of tools such as ChatGPT that produce impressive results.
There has been an explosion of publicly available tools that use machine learning models to deliver content to users. These tools have many benefits, from automating processes to improving reliance in forecasting. However, it’s also important to understand that machine learning isn’t a definitive solution to all problems; the complexity of machine learning models makes it difficult to explain the steps taken to reach the end results, which could cause issues when problems are centred around legal environments, for example. So, whilst ML can act as a powerful tool for businesses, it is important to evaluate whether machine learning is appropriate on a case-by-case basis.


Given the complexity of ML models, it can be overwhelming for newcomers to find a way to harness the power that comes with this emerging technology. However, the barrier to using ML is being lowered by the increasing adoption of low-code platforms that make ML easier to use. A white paper published by Mendix highlights that AI-based applications can use either API calls or embedded machine learning models to create “smart apps” [2]. In both of these scenarios, there is the potential for businesses to build on top of existing ML models instead of having to go through the complex process of creating new models. Other benefits of combining machine learning with low-code include:
- Faster deployment of ML models through low-code’s agile environment.
- Enhanced reusability whereby one machine learning model can be used for multiple applications.
- Automating data processing, such as user input, ensuring a base line of data quality entering ML models.
- Improved visualisation through code abstraction, enhancing interpretability of processes before and after ML model interaction.
These benefits directly address some of the current drawbacks in ML applications, particularly around data quality and explanation of model results. In addition, low-code also helps to reduce the barrier of perceived complexity that prevents businesses and developers alike from implementing ML models. The combination of low-code and ML therefore has real potential to improve the usability of emerging AI technologies.
Machine learning with Mendix
When working with machine learning models, challenges beyond configuring the model can include providing a suitable front-end to the model. With many models requiring human input, a suitable user experience is required to allow anyone to interact with the model, regardless of their knowledge of AI. However, introducing human input means that the quality of data becomes uncertain, a real challenge for machine learning where data richness is essential. Through Mendix’s ability to automate data processes with microflows, the Mendix platform has the potential to provide the much-needed user experience for machine learning models. Previously, Mendix has allowed machine learning models to be integrated through REST APIs. However, this can result in increased cost and maintenance through hosting. Additionally, a reliance on a third-party can introduce security concerns and result in a lack of understanding on machine learning models from the developer’s standpoint. So, whilst using API calls can be an appropriate solution when using large online tools, such as ChatGPT, the additional considerations can be inappropriate when using smaller ML models or when models play a critical role in an application’s functionality.


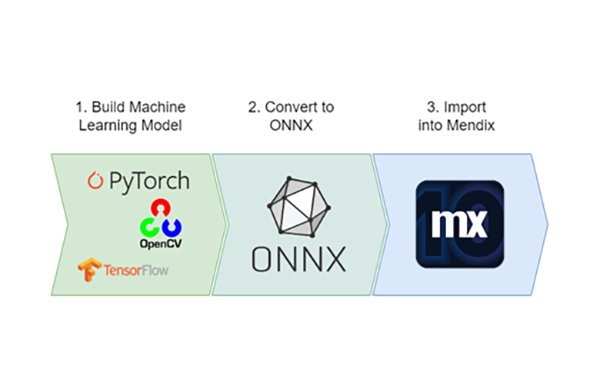
Mendix 10 has introduced increased operability for AI with their Machine Learning Kit (ML Kit). This new feature allows Open Neural Network Exchange (ONNX) models – an open format for machine learning models – to be imported. By using this format, the gap between AI frameworks and Mendix can be bridged without using REST APIs. Instead, ONNX models are imported using ML Model Mapping to allow for interaction in the Mendix environment. By providing the ability to deploy models into the runtime of an application, developers now have greater control over ML capabilities when using Mendix.
Implementing ONNX into Mendix
Using ML Model Mapping in Mendix automatically creates non-persistent entities that map to the inputs and outputs of the imported model. These generated objects act as a means of communication between the user and the ONNX model. However, because these entities are mapped to the model, their attributes are unlikely to match those of the user inputs. To enable seamless interaction between users and the machine learning model, pre-processing and post-processing are often required. Since most machine learning models use tensors – mathematically based objects – any user input (images, text, etc.) need to be converted into this tensor format. This conversion is unique for each model and requires the structure of data to match that of the ML mapping. Consequently, proper pre-processing will assist in obtaining accurate results from the model.
Whilst some simpler models can be controlled solely using microflows, more complex conversions of user inputs into a readable state for machine learning models will require Java actions. Mendix provides guidance on pre/post-processing implementations. This requires knowledge on the developer’s side on converting data types in Java. Once the user input has been converted appropriately for the model’s requirements, interaction with the ML model can start.
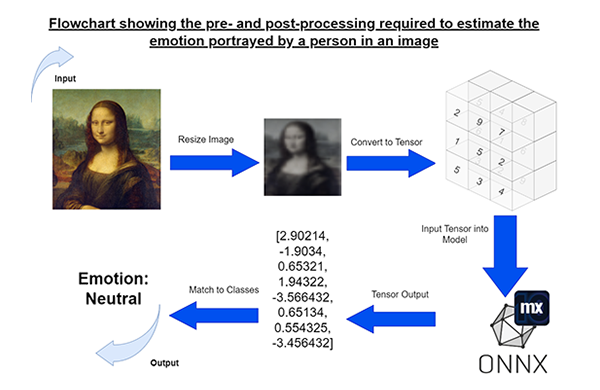
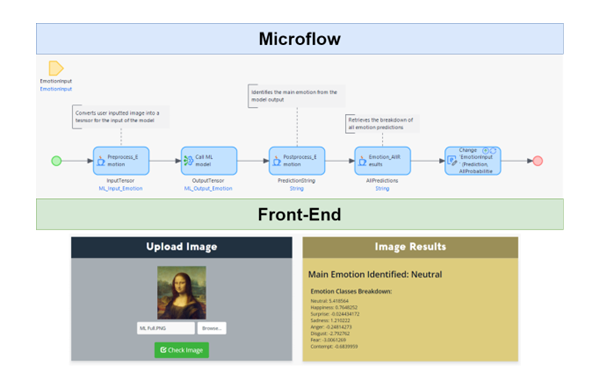
The outcome of converting user inputs means that users can interact with Mendix applications without requiring any additional steps. In the example, a pre-trained model that detects facial emotions in images was implemented. With microflow and Java actions, users only need to upload an image like any regular form to interact with the model.
Conclusion
The toughest part of implementing machine learning models into Mendix is the pre/post-processing activities required. However, most publicly available ONNX models provide instructions on how to properly process user data to be accepted into the models. After this hurdle, providing interaction with the models is standard Mendix development. With calling the ML model through microflow actions, greater control of data is handed to developers, whereby outputs of ML models can be saved as an object in Mendix or even be passed onto another ML model. This allows Mendix to harness the power provided by constantly evolving AI projects being released.
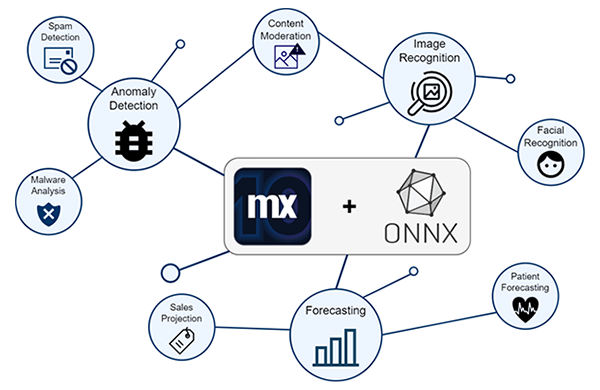
The example implementation in this blog has just focused on one use-case using Mendix’s machine learning capabilities. ML Kit can be expanded to be used for anything from anomaly detection for spam filters to forecasting for expanding business. With the addition of simpler integration and improved performance compared to older methods of interacting with models, Mendix projects can see enhanced interaction with the assistance of AI. With the Mendix environment helping provide quality data that can be automatically processed, the future of low-code AI applications is abundant with opportunities!
Related Blogs



Drag